目前人工智能和大数据火热,使用的场景也越来越广,日常开发中前端同学也逐渐接触了更多与大数据相关的开发需求。因此对大数据知识也有必要进行一些学习理解。
基础概念
大数据的本质
一、数据的存储:分布式文件系统(分布式存储)
二、数据的计算:分部署计算
基础知识
学习大数据需要具备Java知识基础及Linux知识基础
学习路线
(1)Java基础和Linux基础
(2)Hadoop的学习:体系结构、原理、编程
第一阶段:HDFS、MapReduce、HBase(NoSQL数据库)
第二阶段:数据分析引擎 -> Hive、Pig
数据采集引擎 -> Sqoop、Flume
第三阶段:HUE:Web管理工具
ZooKeeper:实现Hadoop的HA Oozie:工作流引擎
(3)Spark的学习
第一阶段:Scala编程语言
第二阶段:Spark Core -> 基于内存、数据的计算
第三阶段:Spark SQL -> 类似于mysql 的sql语句
第四阶段:Spark Streaming ->进行流式计算:比如:自来水厂
(4)Apache Storm 类似:Spark Streaming ->进行流式计算
NoSQL:Redis基于内存的数据库
HDFS
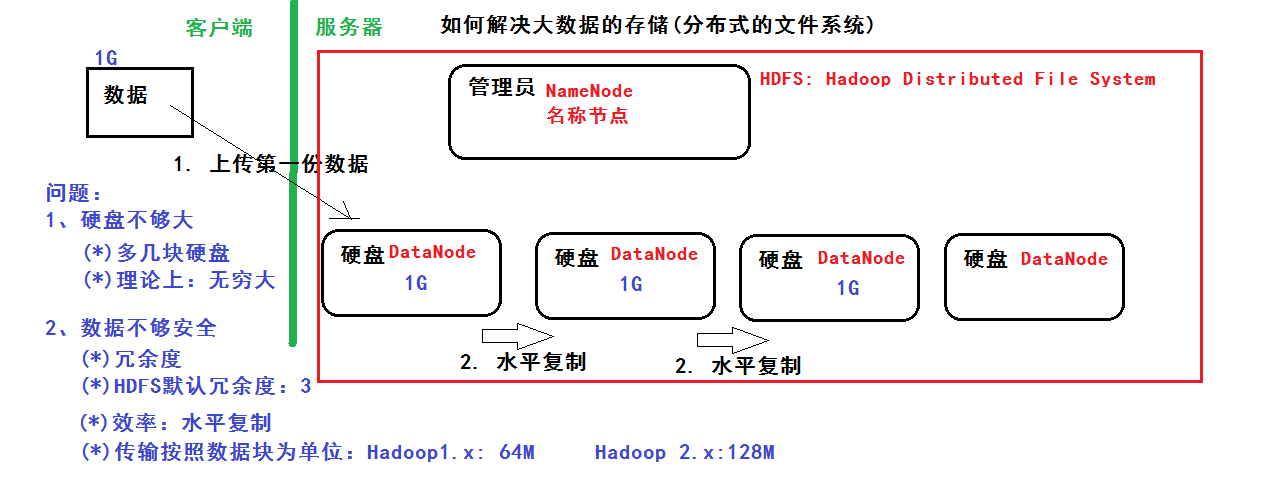
分布式文件系统 解决以下问题:
• 硬盘不够大:多几块硬盘,理论上可以无限大
• 数据不够安全:冗余度,hdfs默认冗余为3 ,用水平复制提高效率,传输按照数据库为单位:Hadoop1.x 64M,Hadoop2.x 128M
• 管理员:NameNode 硬盘:DataNode
MapReduce
基础编程模型:把一个大任务拆分成小任务,再进行汇总
• MR任务:Job = Map + Reduce
Map的输出是Reduce的输入、MR的输入和输出都是在HDFS
MapReduce数据流程分析:
• Map的输出是Reduce的输入,Reduce的输入是Map的集合
在这里我还是要推荐下我自己建的大数据学习交流qq裙:522189307 , 裙 里都是学大数据开发的,如果你正在学习大数据 ,小编欢迎你加入,大家都是软件开发党,不定期分享干货(只有大数据开发相关的),包括我自己整理的一份最新的大数据进阶资料和高级开发教程,欢迎进阶中和进想深入大数据的小伙伴。上述资料加群可以领取
HBase
什么是BigTable?: 把所有的数据保存到一张表中,采用冗余 ---> 好处:提高效率
• 因为有了bigtable的思想:NoSQL:HBase数据库
• HBase基于Hadoop的HDFS的
• 描述HBase的表结构
核心思想是:利用空间换效率
Hadoop环境搭建
环境准备
Linux环境、JDK、http://mirrors.shu.edu.cn/apache/hadoop/common/hadoop-3.0.0/hadoop-3.0.0-src.tar.gz
安装
1、安装jdk、并配置环境变量
vim /etc/profile 末尾添加 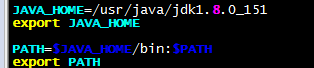
2、解压hadoop-3.0.0.tar.gz、并配置环境变量
tar -zxvf hadoop-3.0.0.tar.gz -C /usr/local/ mv hadoop-3.0.0/ hadoop
vim /etc/profile 末尾添加
配置
Hadoop有三种安装模式:
本地模式 :
• 1台主机 • 不具备HDFS,只能测试MapReduce程序
伪分布模式:
• 1台主机 • 具备Hadoop的所有功能,在单机上模拟一个分布式的环境 • (1)HDFS:主:NameNode,数据节点:DataNode • (2)Yarn:容器,运行MapReduce程序 • 主节点:ResourceManager • 从节点:NodeManager
全分布模式:
• 至少3台
我们以伪分布模式为例配置:
修改hdfs-site.xml:冗余度1、权限检查false
修改core-site.xml
修改mapred-site.xml
修改yarn-site.xml
格式化NameNode
hdfs namenode -format
看到common.Storage: Storage directory /usr/local/hadoop/tmp/dfs/name has been successfully formatted表示格式化成功
启动
start-all.sh
(*)HDFS:存储数据
(*)YARN:
访问
HDFS: http://192.168.56.102:50070
Yarn: http://192.168.56.102:8088
查看HDFS管理界面和yarn资源管理系统
基本操作:
HDFS相关命令
MapReduce示例
结果:
如上 一个最简单的MapReduce示例就执行成功了
思考
Hadoop是基于Java语言的,前端日常开发是用的PHP,在使用、查找错误时还是蛮吃力的。工作之余还是需要多补充点其它语言的相关知识,编程语言是我们开发、学习的工具,而不应成为限制我们技术成长的瓶颈