今天主要讲开发中比较常用的HaspMap、TreeMap.
方法归类 map集合中存放的都是一组组映射关系 key=value,map集合key不能重复,在集合中也允许嵌套集合
1、增加 put(K key, V value) putAll(Map<? extends K,? extends V> m) 2、删除 clear() remove(Object key) 3、判断 containsKey(Object key) containsValue(Object value) isEmpty() 4、获取 get(Object key) size() values() entrySet() keySet()put(增加方法) :添加集合元素的同时,它可以编辑原有的元素 * 如果集合中没有Key对应的value,那么就往集合中添加元素 * 如果说集合对应的key有value值,则代表替换原有的值 * * 2.返回替换前key对应value值 注意:
添加元素时,如果键已经在集合中存在,那么后添加的值会覆盖原来的值,并且put方法会将原有的值返回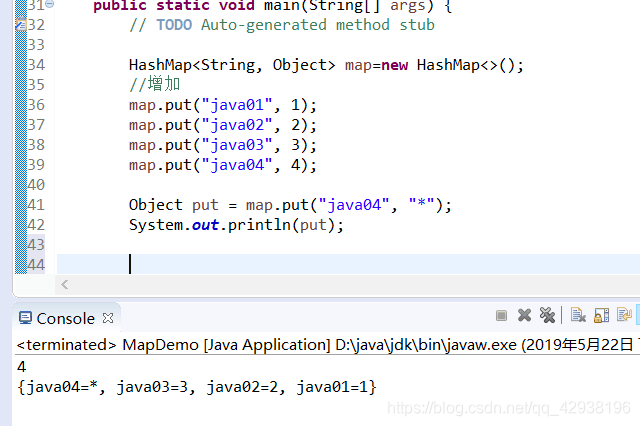entrySet() keySet() entrySet():entry本身是个类,这个类是属于Map集合里,在遍历时候将一对键值取出来从而达到遍历效果,图解: keySet() 而keyset是用键去一一对应的找到其所属的值,这样遍历效率相对于entryset低效一些。图解:
以上是一些比较常用的方法,想了解更多可以参考文档http://tool.oschina.net/apidocs/apidoc?api=jdk-zh
例如:1、将学生作为键,地址作为值进行存储,名字年龄相同则被认定为一个人,最后输 2、最后按年龄进行排序 3、需求改变、按姓名进行排序
这里的话参考我前几篇的博客,这个需求相对于来说还是可以解决开发出来的
这个面试题出现的频率很高,在我求职的面试里,基本每家都会问到这个问题。 统计字符串中字出现的次数 例如:(addfghjhjkl a(1) d(2))
思考
统计.排序
统计功能
1.将这个字符串中的字符当作map集合中的key,将出现的次数作为value值
2.当字符第一次出现的时候,那么用它在集合中进行寻找,返回值必然为Null,
之后将该字符对应的值改为1
3.如果说该字符不是第一次出现,该字符对应值不为null,然后应该+1
先写一个字符出现次数统计的方法
之后就会打印如下图: 最后排序:只需要将最开始写的HashMap 该成TreeMap即可达到最后的效果,一道面试题就完成了!!!
小结:
Map Hashtable:底层是哈希表数据结构,不可以存入null键null值,该集合石线程同步的,jdk1.0,效率低 HashMap:底层是哈希表数据结构,允许使用null值和null键,该集合是不同步的。将Hashtable替代;jdk1.2,效率高 TreeMap:底层是二叉树数据结构,线程不同步,可以用于给Map集合中的键进行排序